🤖 Inference APIs
APIs and runtimes for AI models, especially LLMs, enable powerful text generation and processing in apps. They serve as the foundation for many AI solutions and allow easy integration, making advanced AI accessible for developers.
79 tools
Featured
Hosted Inference APIs 44
Norwegian cloud platform with an OpenAI-compatible LLM API running open-weight models in Oslo
OpenAI-compatible API for open-weight LLMs and image models, hosted in IONOS EU data centers







European sovereign AI inference with OpenAI-compatible APIs hosted in EU datacenters
Run AI models at the edge on Cloudflare's global network with serverless inference

Custom AI chip inference platform with purpose-built hardware for high-throughput LLM serving
Unified API for 400+ AI models across 60+ providers, OpenAI SDK-compatible, pay-as-you-go
Google's API for Gemini models with text, image, video, and audio capabilities
Managed API access to foundation models on AWS with built-in fine-tuning and agent tooling
Cost-effective inference API with OpenAI-compatible endpoints and open-weight models




Claude API for building AI applications with Opus, Sonnet, and Haiku models



LPU-powered inference API for LLMs, speech, and vision models with usage-based pricing





GPU Clouds 19


Sovereign AI inference infrastructure for regulated EU environments, with heterogeneous GPU support

Decentralized GPU cloud for AI inference, training, and containerized workloads










Serverless GPU 8


Open-source serverless GPU cloud with sub-second cold starts and auto-scaling






Other 7

Unified API for hundreds of AI models, with built-in rate limiting and key management
Web-grounded AI answers API with citations, OpenAI-compatible, pay-per-query pricing

High-throughput LLM inference engine with PagedAttention for efficient GPU memory usage

Inference APIs overview
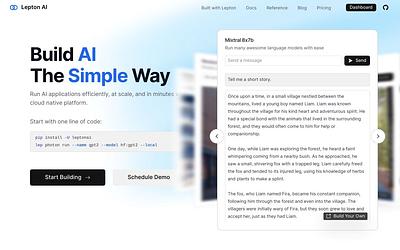
Inference API providers give developers access to large language models without managing GPU infrastructure. These services expose model endpoints via REST or gRPC APIs, handling scaling, load balancing, and hardware optimization behind the scenes. Most support the current open-source frontier (gpt-oss-20B and gpt-oss-120B, Kimi K2 family, Qwen3.5 family, GLM-5, DeepSeek V3.2, MiniMax-M2, NVIDIA Nemotron) alongside Meta Llama 3.x and 4.x and proprietary offerings.
The competitive landscape has shifted toward speed and cost efficiency. Providers differentiate on sustained throughput (tokens per second), time-to-first-token latency, supported model catalog, and pricing models (per-token, per-request, or reserved capacity). Custom inference hardware from Cerebras and Groq competes with GPU-based providers like DeepInfra, Together.ai, Fireworks, and Novita on different metrics. OpenRouter provides a unified gateway that routes requests across providers from a single API.
For teams building production applications, the choice of inference provider affects user experience directly. Factors like geographic availability, uptime SLAs, streaming support, function calling, structured outputs, fine-tuning options, and batch inference pricing all matter when selecting a provider.
Related stacks
See how inference apis tools fit into a full infrastructure stack.
Frequently Asked Questions
What is an LLM inference API?
An LLM inference API is a hosted service that runs large language model predictions on your behalf. You send prompts via HTTP requests and receive generated text back. The provider handles GPU allocation, model loading, scaling, and optimization, so you can focus on building your application.
How do I choose between inference API providers?
Consider latency requirements, supported models, pricing structure, geographic availability, and features like streaming, function calling, and batch processing. Run benchmarks with your actual workload, as performance varies significantly by model size and prompt length.
Is it cheaper to self-host or use an inference API?
For most teams, inference APIs are more cost-effective until you reach consistent high-volume usage. Self-hosting requires GPU procurement, ops expertise, and handling idle capacity. APIs let you pay per token and scale elastically. The break-even point depends on your traffic patterns and model choices.
What is time-to-first-token and why does it matter?
Time-to-first-token (TTFT) measures the delay between sending a request and receiving the first token of the response. Lower TTFT creates a more responsive user experience, especially in chat interfaces. It is influenced by model size, hardware, request queue depth, and whether the provider uses speculative decoding or other optimization techniques.
Is your product missing?