
Turbopuffer
Serverless vector and full-text search engine built on object storage for cost-efficient scale
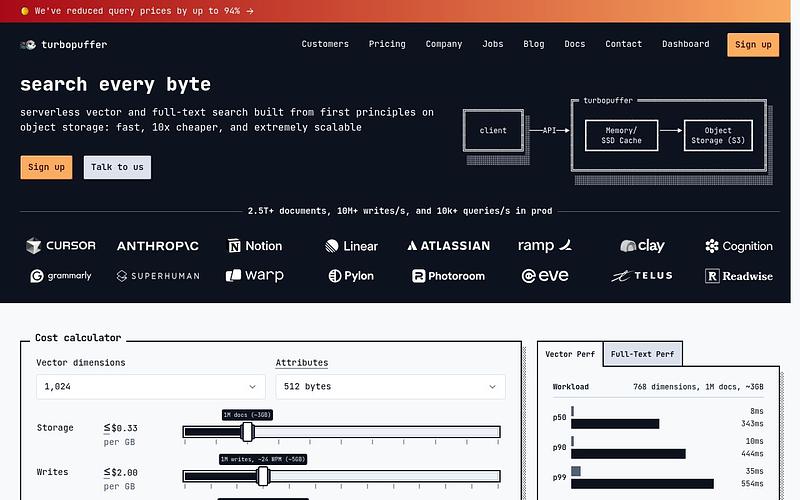
Turbopuffer is a serverless vector and full-text search engine that stores data on object storage (S3, GCS, Azure Blob) with tiered caching through NVMe SSDs and RAM. It supports both dense vector similarity search and BM25 full-text search. The architecture handles 2.5T+ documents with sub-10ms p50 latency for cached queries, at roughly 10x lower cost than alternatives. Storage starts at $70/TB/month. Used by Cursor, Notion, Linear, Superhuman, and Grammarly.
Pricing: Usage-based
What is Turbopuffer?
Turbopuffer is a serverless vector and full-text search database built on object storage (S3, GCS, Azure Blob). Founded by ex-Shopify engineers Simon Eskildsen and Justin Li, it takes a fundamentally different approach to search infrastructure by using cheap object storage as the source of truth and layering SSD and memory caches on top. This architecture delivers 10-20x cost savings over traditional vector databases.
How It Works
Turbopuffer uses a three-tier storage hierarchy. Cold data lives on object storage (~$0.02/GB), warm data is cached on NVMe SSDs, and hot data sits in memory. The more you query a namespace, the faster it gets, as data moves up the tiers automatically. Writes go through a write-ahead log on object storage for durability, supporting roughly 10,000+ vectors per second. The system provides strong consistency by default, with an eventually-consistent option for lower latency.
Key Features
The database supports vector similarity search, BM25 full-text search, and hybrid combinations of both with rank fusion. Metadata filtering works on any attribute alongside search. Multi-tenancy is a first-class concern, designed for millions of namespaces (Notion runs 10B+ vectors across millions of namespaces on Turbopuffer). Customers include Cursor, Anthropic, Notion, Linear, Atlassian, Ramp, and Grammarly.
Pricing
Usage-based pricing starts at $64/month (Launch plan) with all database features included. The Scale plan ($256/month) adds HIPAA BAA, SSO, and priority support. Enterprise ($4,096+/month) adds single-tenancy, BYOC, CMEK, and 99.95% SLA. Storage, queries, and writes are billed separately with volume discounts. There is no free tier.
Who Should Use Turbopuffer?
Turbopuffer is a strong choice for teams building RAG pipelines or embedding search at scale, particularly when cost matters. The object-storage-first architecture shines for large datasets (millions to billions of vectors) and multi-tenant use cases. Trade-offs include cold query latency (~300-500ms on first hit to a namespace), a write latency floor around 200ms, and no built-in reranking. It handles first-stage retrieval only, so you implement reranking in your own application code.
Turbopuffer Alternatives
Explore 25 products in the Vector databases category. View all Turbopuffer alternatives.
OpenSearch
Open-source search and analytics suite with full-text, vector, and hybrid search
Meilisearch
Open-source search engine in Rust with full-text, semantic, and hybrid search

Weaviate
Weaviate is an open source, AI-native vector database that helps developers create intuitive and reliable AI-powered ...

Work on Turbopuffer? Feature it at the top of Vector databases.
Is your product missing?