AI Infrastructure Stack
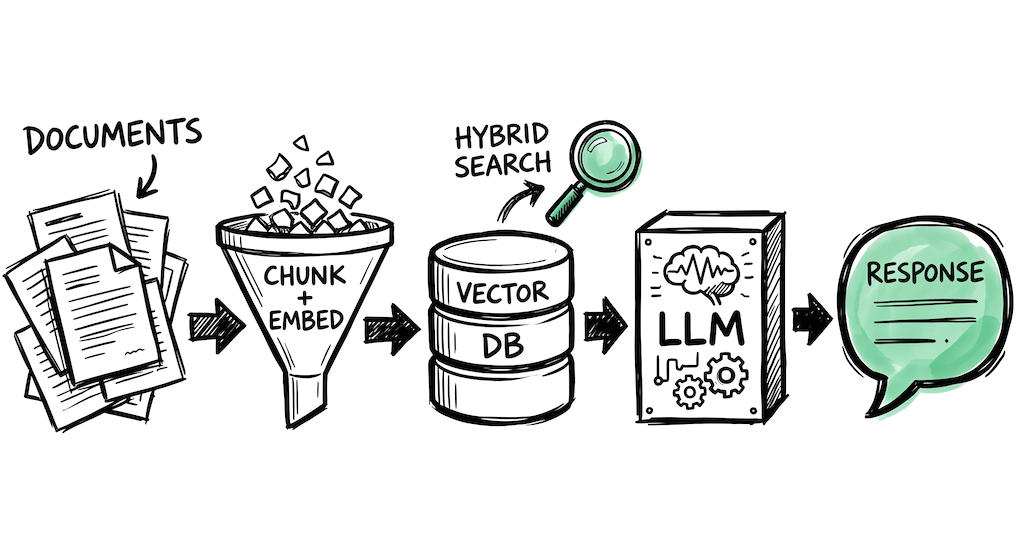
RAG Chatbot Stack
Build a chatbot that answers questions from your own documents, knowledge base, or internal docs. One of the most common first AI projects developers take on.
Inference & Embeddings
☁️A RAG chatbot needs two types of model calls: an embedding model to turn documents and queries into vectors, and a chat model to generate answers from retrieved context. You can use different providers for each.

text-embedding-3-small is the default starting point for embeddings (good cost/quality balance). GPT-4o or GPT-4.1 for generation. Most tutorials and frameworks assume OpenAI.

embed-v4 for multilingual embeddings (100+ languages). Includes a built-in Rerank API for improving retrieval precision. Good if your docs are in multiple languages.

Run open-source embedding models (BGE, E5) and chat models at low cost. Good for production workloads where per-token pricing matters.
Vector Database
🗄️Stores your document embeddings and retrieves relevant chunks at query time. The biggest practical tip: use hybrid search (vector + keyword/BM25) from the start. Vector search catches semantics, keyword search catches exact terms, acronyms, and IDs. Combining them with Reciprocal Rank Fusion consistently outperforms either alone.
If you run Postgres, add pgvector for dense search. Pair with PostgreSQL full-text search for basic hybrid retrieval. No extra service to manage. Good up to ~10M vectors.

Built-in hybrid search combining dense vectors with sparse (keyword) retrieval. Fast filtered search for multi-tenant apps ("only search this user's documents").

Native hybrid search with BM25 + vector in a single query. Built-in vectorization modules can embed at ingestion time. Good for teams that want fewer moving parts.
Framework
🔧For a basic RAG pipeline, you can build it yourself with the provider SDK + a vector DB client. A framework helps when you need advanced chunking strategies, multiple data sources, or reranking. LlamaIndex has the edge here specifically because RAG is its core focus.

Purpose-built for RAG. 160+ data connectors, semantic chunking, parent-child retrieval, hybrid search orchestration. The standard choice when your core problem is search quality over documents.

Modular pipeline architecture from deepset (Berlin). Strong document parsing and preprocessing. Used in production by Airbus and The Economist. More opinionated than LlamaIndex.

Largest ecosystem and most tutorials. For RAG specifically, LlamaIndex and Haystack tend to be recommended over LangChain by teams focused on retrieval quality. Better suited when RAG is one part of a larger agent system.
Evaluation & Observability
🔍RAG systems degrade silently. Documents change, embeddings go stale, retrieval quality drifts. Without evaluation, you are relying on user complaints to find problems. Start with a small set of question-answer pairs from real usage and measure from day one.

Trace the full RAG pipeline: which chunks were retrieved, what prompt was sent, what the model returned. Framework-agnostic. Free tier with 50K events/month.

Evaluation-focused. Build datasets, run your RAG pipeline against them, score with custom metrics. Catches quality regressions before users do.
Open-source evaluation framework for LLMs. Includes RAG-specific metrics (faithfulness, answer relevancy, context precision). Integrates with pytest for CI/CD.
Things to keep in mind
- Most RAG failures trace back to chunking, not the model or the vector database. Invest in smart chunking (semantic boundaries, parent-child) before tuning anything else.
- Hybrid search (vector + keyword) is one of the most impactful retrieval improvements you can make. It takes a few hours to set up and the gains are usually visible immediately.
- Changing your embedding model means re-indexing everything. Pick one early, benchmark on your actual documents, and commit. text-embedding-3-small is a safe starting point.
- A reranker between retrieval and generation can improve answer quality. The pattern: retrieve broadly (top 20), rerank precisely (top 5), send only the best chunks to the LLM.
Frequently asked questions
What tools do I need to build a RAG chatbot?
An embedding model to vectorize documents, a vector database to store and search them, an LLM to generate answers from retrieved context, and optionally a framework like LlamaIndex to handle chunking and retrieval logic.
What is hybrid search and why does it matter for RAG?
Hybrid search combines vector similarity search with keyword search (BM25) and merges results using Reciprocal Rank Fusion. Vector search catches semantics while keyword search catches exact terms, acronyms, and IDs. Using both consistently outperforms either alone.
Which embedding model should I use for RAG?
OpenAI text-embedding-3-small is a safe starting point with good cost and quality balance. For multilingual documents, Cohere embed-v4 handles 100+ languages. Changing embedding models requires re-indexing all documents, so benchmark on your actual data before committing.
How do I evaluate RAG quality?
Build a small set of question-answer pairs from real usage and measure context precision (are the right chunks retrieved?), faithfulness (does the answer stick to the context?), and answer relevancy. Tools like DeepEval and Braintrust can automate this.
Last updated: April 2026

Is your product missing?