AI Infrastructure Stack
Voice AI Stack
Transcription, text-to-speech, and voice agents. Whether you are adding voice features to an existing product or building a standalone audio pipeline, these are the building blocks.
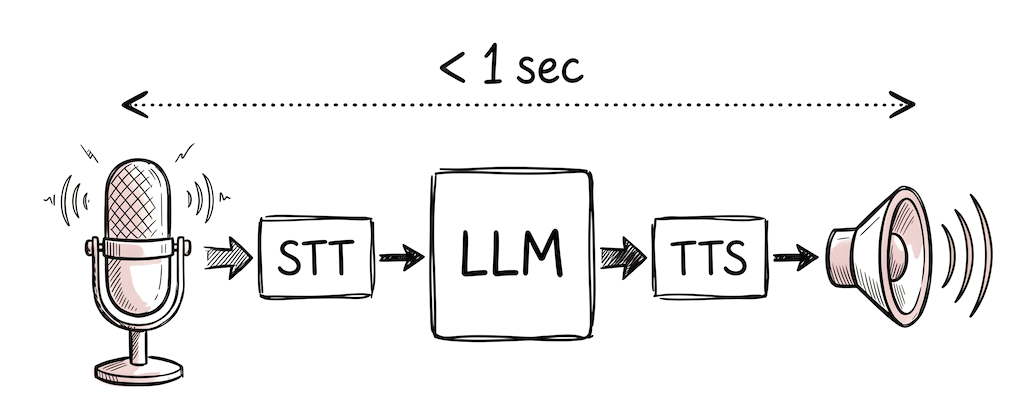
How a voice AI pipeline works
A voice AI pipeline chains three components: speech-to-text (STT) transcribes audio into text, a language model processes the text and generates a response, and text-to-speech (TTS) turns that response back into audio. For real-time voice agents, this entire loop needs to complete in under 1 second for conversation to feel natural.
There are two architectural approaches. A cascading pipeline (STT → LLM → TTS) processes each stage sequentially and is simpler to build and debug. A speech-to-speech model handles audio in and audio out natively, reducing latency but offering less control over each stage. Most production voice agents in 2026 use the cascading approach with streaming at every stage to minimize perceived delay.
The choice of provider at each layer depends on the use case. Real-time voice agents need low streaming latency above all. Batch transcription (meeting notes, podcast processing) prioritizes accuracy and cost per audio hour. Content generation (audiobooks, video narration) prioritizes voice quality and expressiveness over speed.
Transcription (Speech-to-Text)
🎤Turn audio into text. For real-time use cases (live captions, voice agents), streaming latency matters. For batch processing (meeting notes, podcast transcription), accuracy and cost per hour matter more.

Nova-3 model. The most used API for real-time voice agents. Streaming latency under 300ms, good noise robustness. 36 languages.

Universal-2 model with strong accuracy. Also offers Slam-1 speech-language model that combines transcription with understanding. Good for structured audio analysis.

French company (EU-hosted). Solaria model with anti-hallucination features. Strong on multilingual transcription and code-switching (mixing languages in one stream).
Text-to-Speech
🔊Generate spoken audio from text. For voice agents, time-to-first-audio (TTFA) is critical, you want the user to hear something within 100ms. For content generation (audiobooks, videos), voice quality and expressiveness matter more.
Flash v2.5 for low-latency voice agents, Eleven v3 for higher quality output. Voice cloning and 74 languages. The largest TTS provider by adoption.

Sonic 3 model. Very low time-to-first-audio, purpose-built for real-time voice agents. Competitive pricing per character.

TTS API with multiple voices. Straightforward to use if you are already on the OpenAI platform. Less customizable than ElevenLabs, but simpler integration.
Voice Agent Frameworks
🎙️A voice agent pipeline is: microphone → STT → LLM → TTS → speaker, running in real time. The challenge is orchestrating these steps with low enough latency that conversation feels natural. You can buy a managed platform or build with an open-source framework.
Open-source framework for real-time voice and video agents. WebRTC-native. Plugin system for mixing STT, LLM, and TTS providers. The most popular open-source option for custom voice pipelines.
Conversational AI platform that combines their TTS with an LLM in a managed pipeline. Simpler than building your own if voice quality is the priority.

Emotion-aware voice AI. Their EVI (Empathic Voice Interface) responds to tone and emotional cues. Useful for support and wellness applications.
Things to keep in mind
- For voice agents, the whole pipeline (STT → LLM → TTS) needs to stay under ~1 second total for conversation to feel natural. Each component adds latency, so pick providers with low streaming latency and test the full round trip.
- Self-hosting Whisper is viable for batch transcription but hard to beat the managed APIs on streaming latency and accuracy. If real-time is not a requirement, Whisper large-v3-turbo is a good self-hosted option.
- Voice cloning and custom voices are available from ElevenLabs, Cartesia, and LMNT. If your product has a brand voice, this matters.
- Open-source TTS has improved significantly. Kokoro-82M and Fish Speech are self-hostable with good quality. Worth evaluating if you need to control costs at scale.
Frequently asked questions
What is the best speech-to-text API for real-time use?
Deepgram (Nova-3) is the most used API for real-time voice agents, with streaming latency under 300ms and good noise robustness. AssemblyAI offers strong accuracy. For EU hosting, Gladia (France) is an option.
Which text-to-speech API has the lowest latency?
Cartesia (Sonic 3) and ElevenLabs (Flash v2.5) both offer very low time-to-first-audio for voice agent use cases. For highest voice quality without latency constraints, ElevenLabs Eleven v3 is a common choice.
How do you build a real-time voice agent?
A voice agent pipeline runs: microphone to speech-to-text to LLM to text-to-speech to speaker, all in real time. LiveKit Agents is the most popular open-source framework for this. The target is under 1 second total round-trip latency.
Can I self-host speech-to-text?
Yes. Whisper large-v3-turbo is 6x faster than the original with only a slight accuracy drop. NVIDIA Parakeet is faster still for streaming. Self-hosting is practical for batch transcription but hard to beat managed APIs on streaming latency.
What is a realistic latency budget for a voice AI pipeline?
For a conversational voice agent, the full round trip (STT to LLM to TTS) should stay under 1 second. A typical breakdown: 50ms for voice activity detection, 150ms for STT streaming, 400ms for LLM time-to-first-token, 150ms for TTS first audio chunk, and 50ms for network overhead. Streaming at every stage is the most impactful optimization.
Last updated: April 2026

Is your product missing?